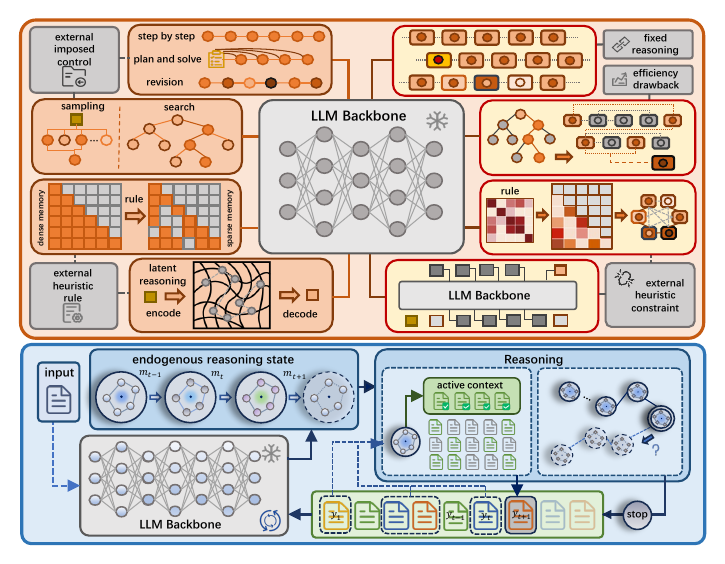
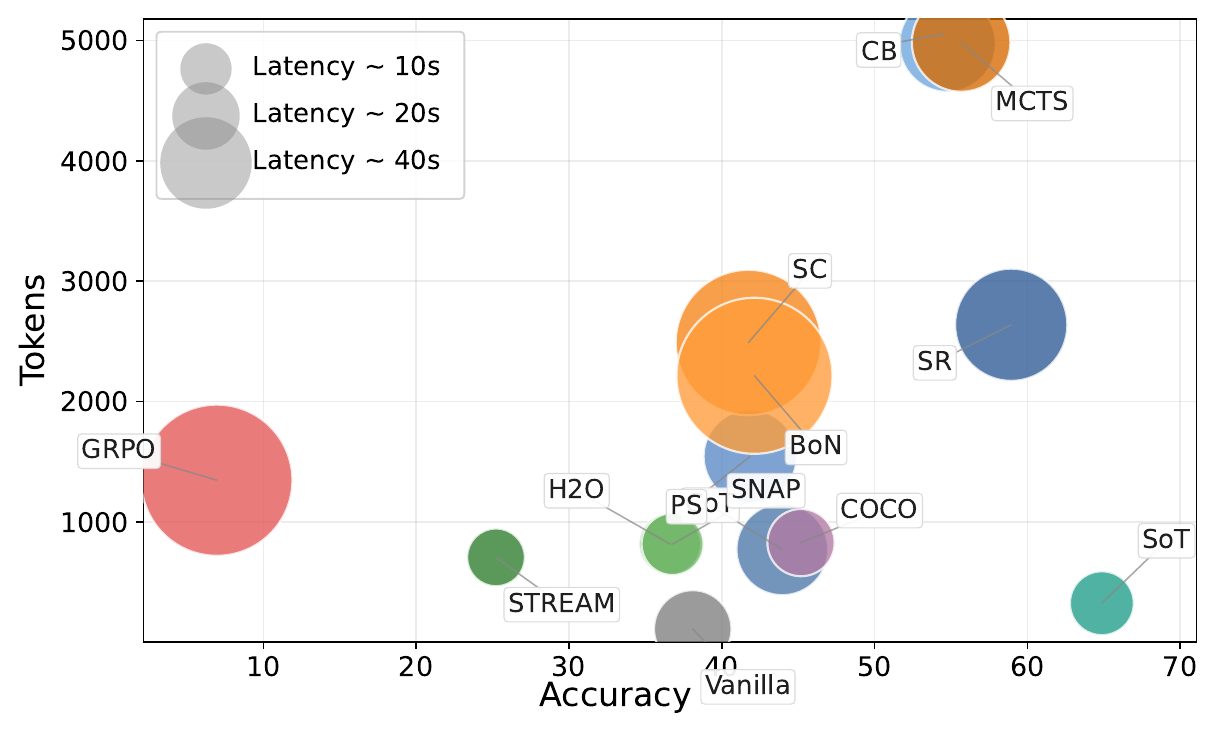
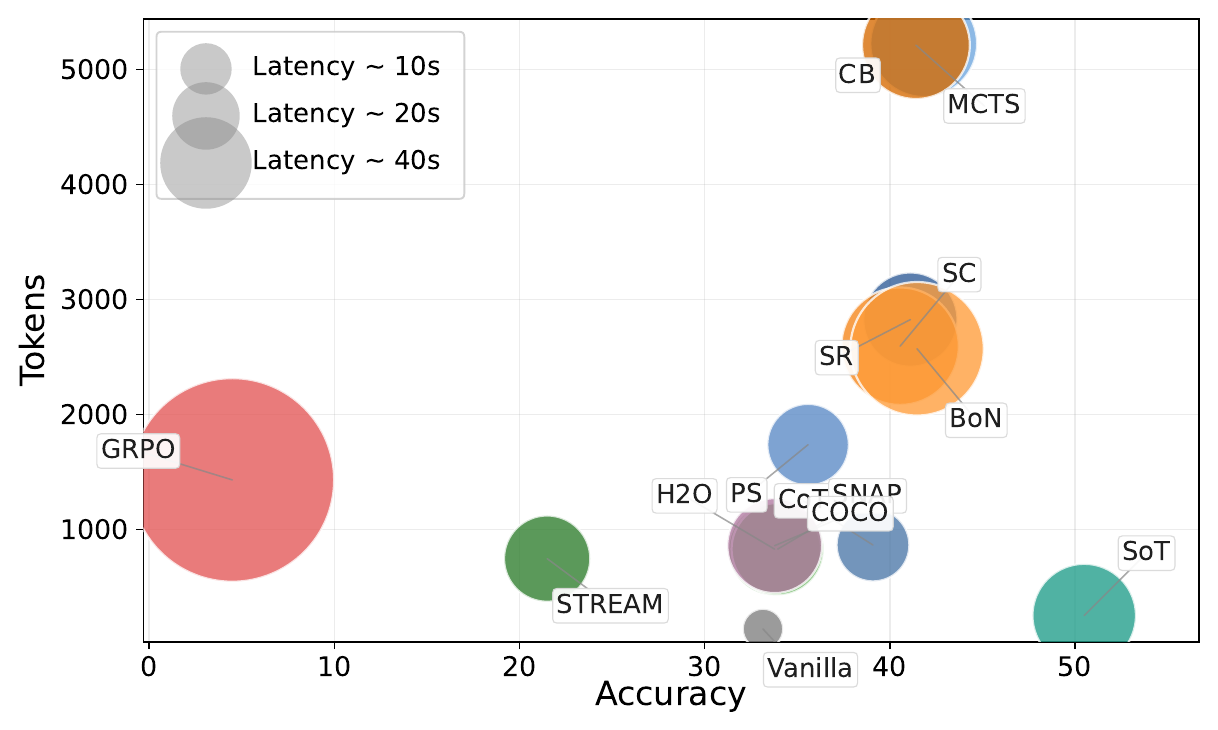
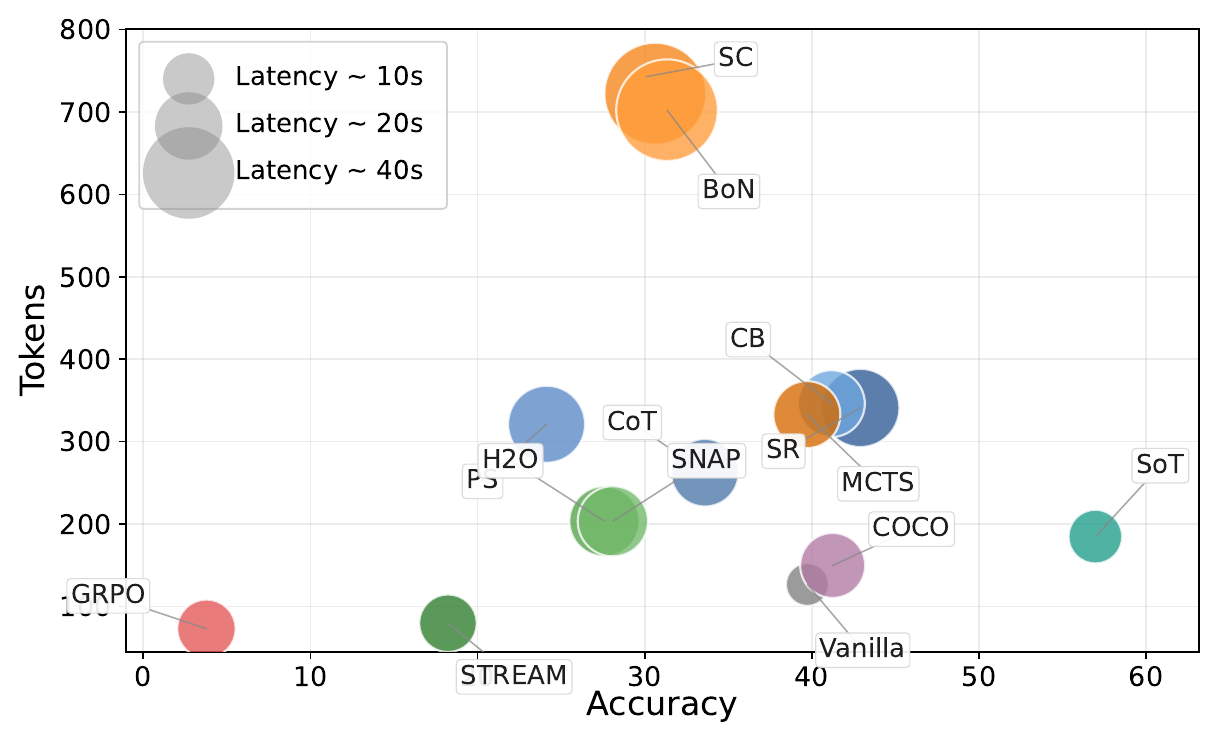
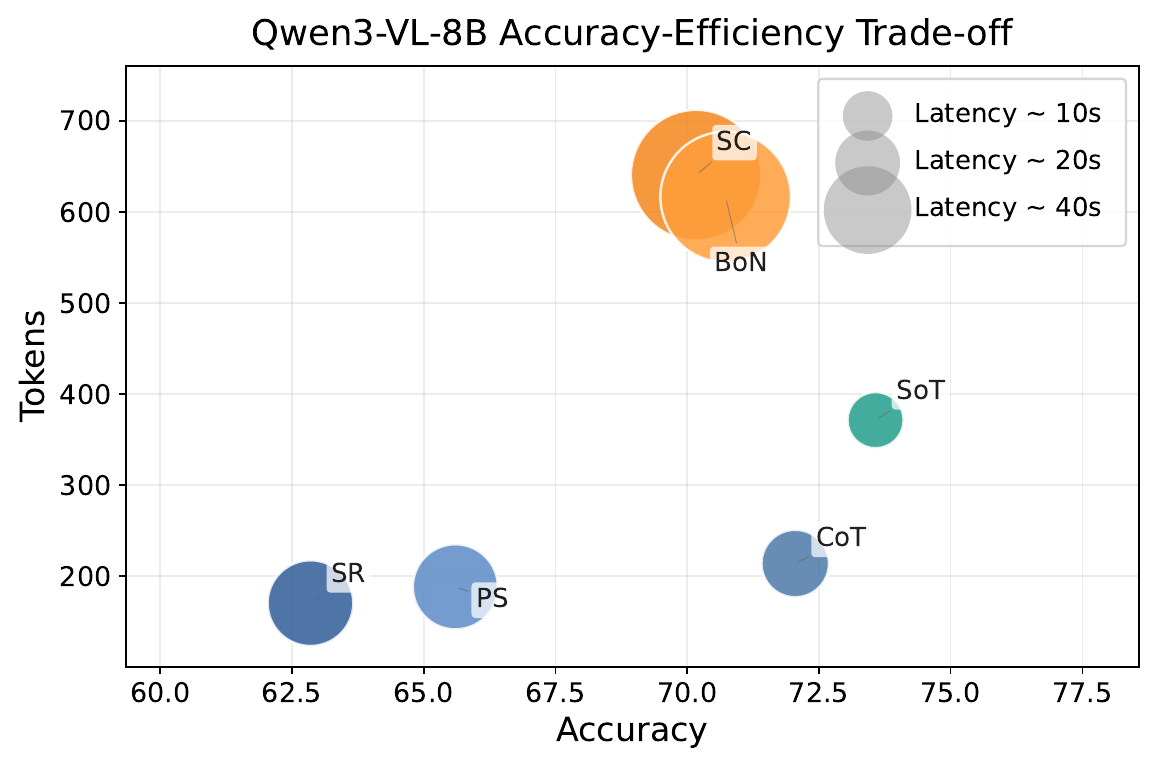
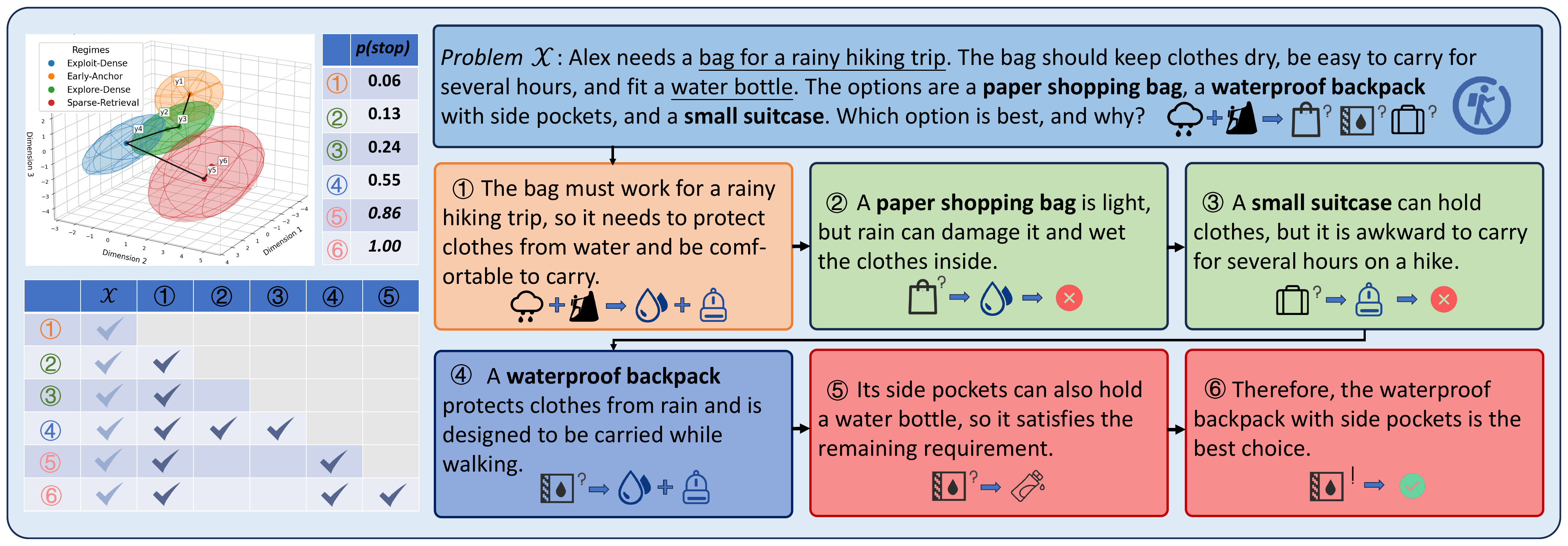
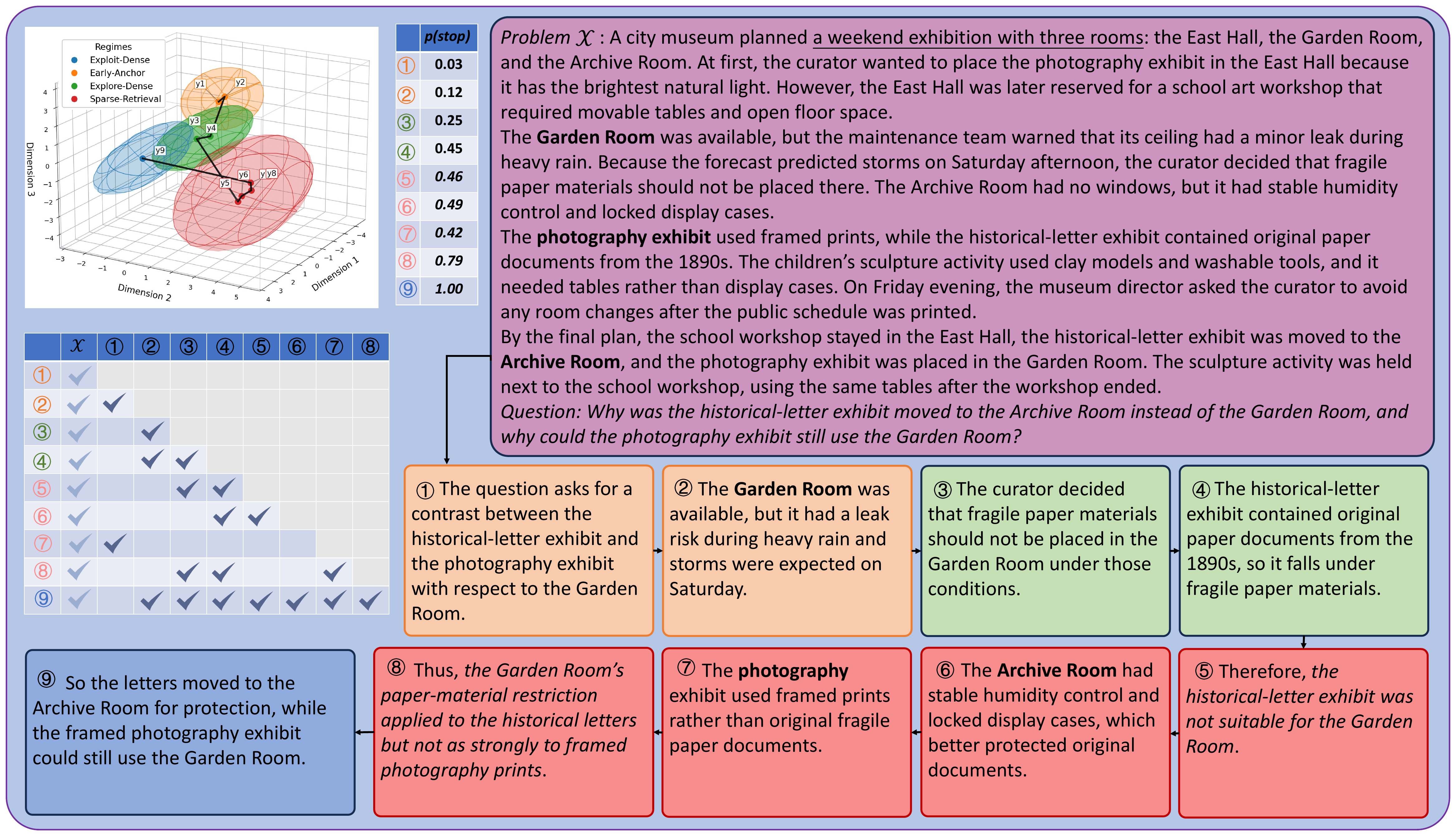
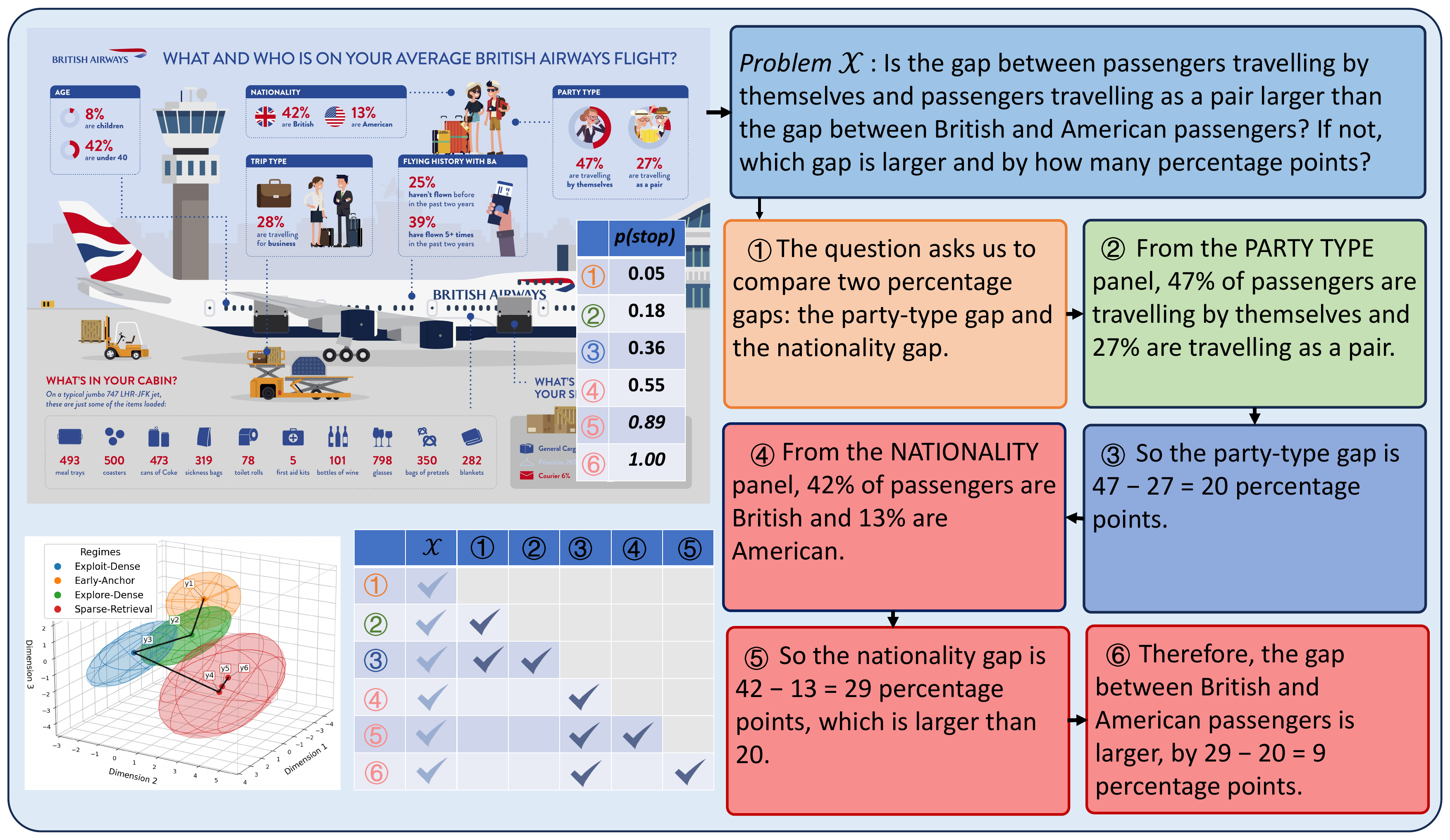
SoT reframes test-time reasoning as a closed loop: the model's endogenous state selects the right historical evidence
for the next step and controls when to stop, rather than following fixed external reasoning programs.
Zhiren Gong1,2, Yikun Hou1,4, Zeng Zihao1, Ming Xiao5,
Chau Yuen3, Wei Yang Bryan Lim1
1 College of Computing and Data Science, Nanyang Technological University
2 Interdisciplinary Graduate Programme, Nanyang Technological University
3 School of Electrical and Electronic Engineering, Nanyang Technological University
4 Department of Mathematics and Mathematical Statistics, Umea University
5 Department of Information Science and Engineering, Royal Institute of Technology, Sweden