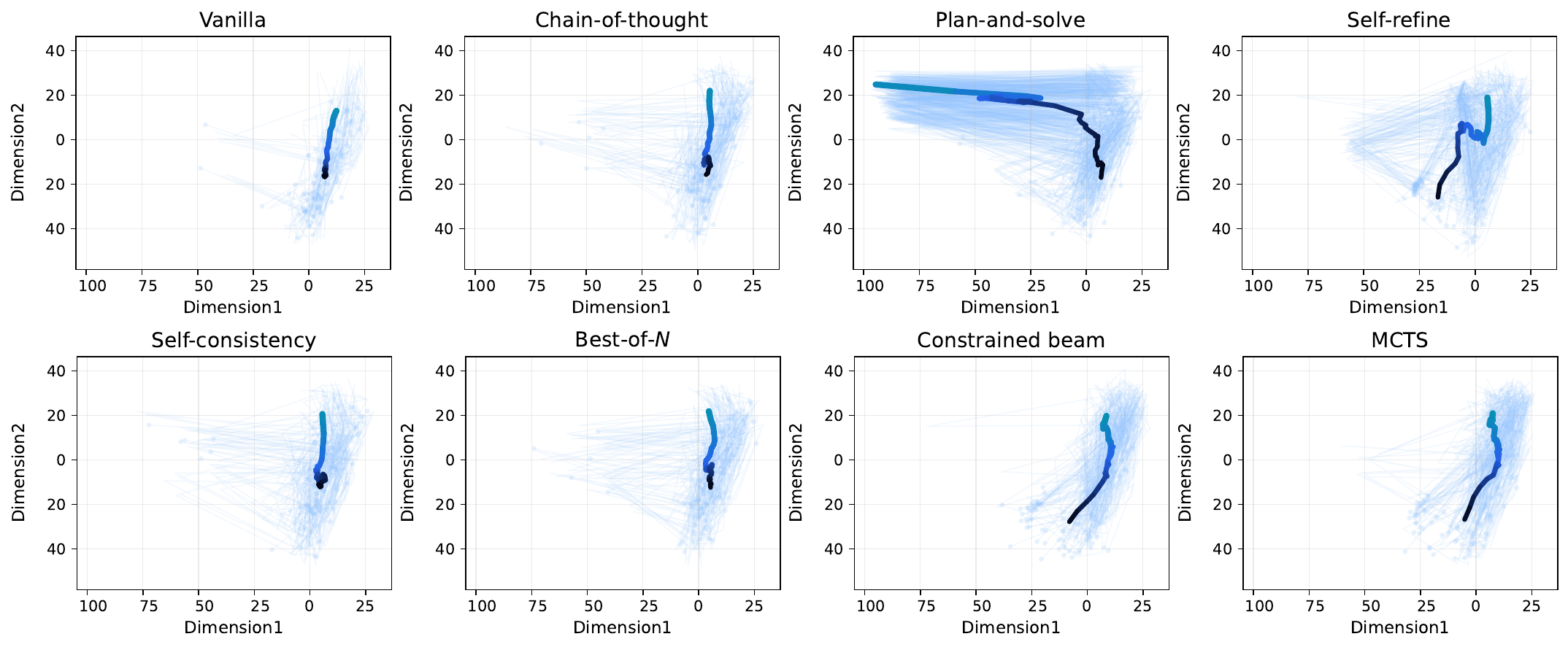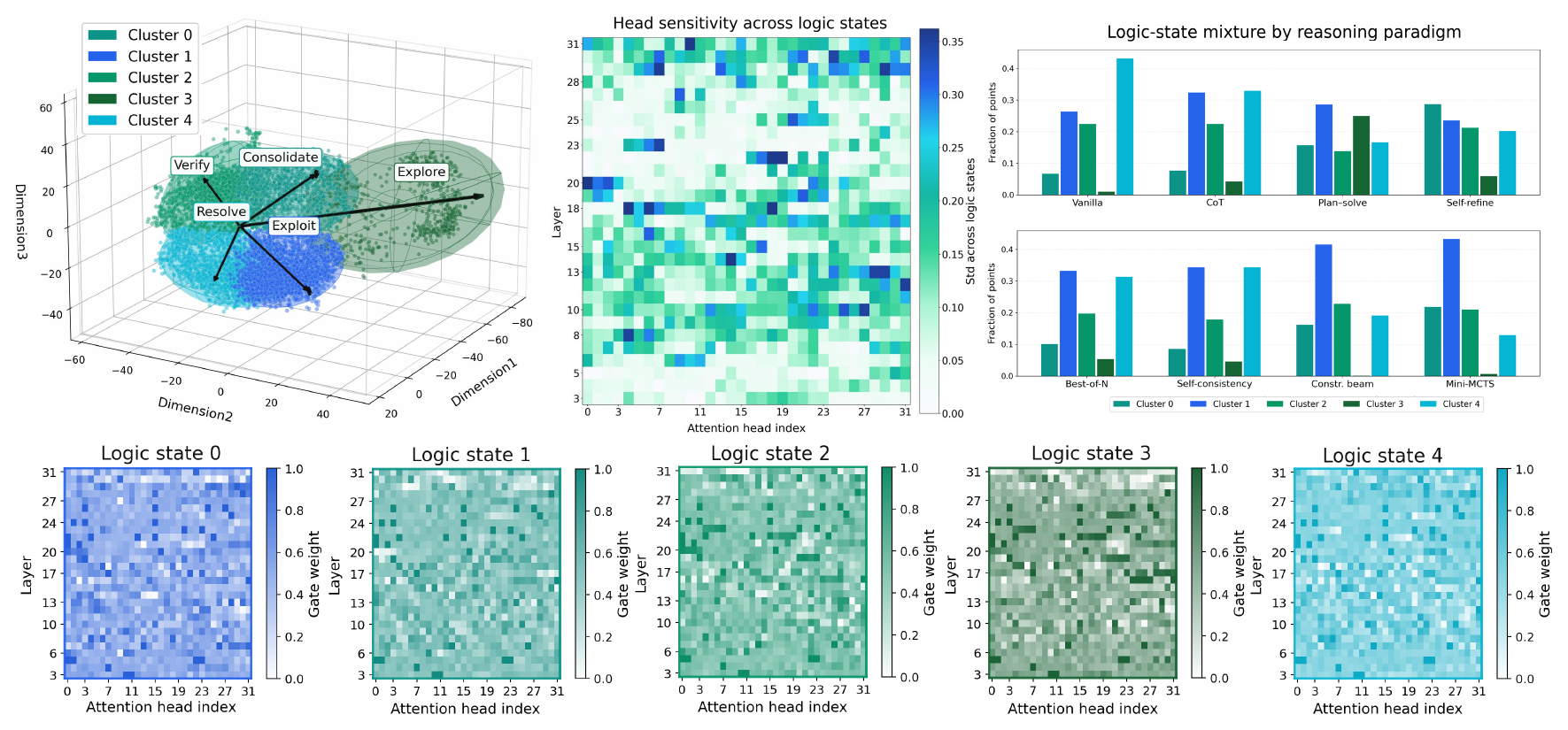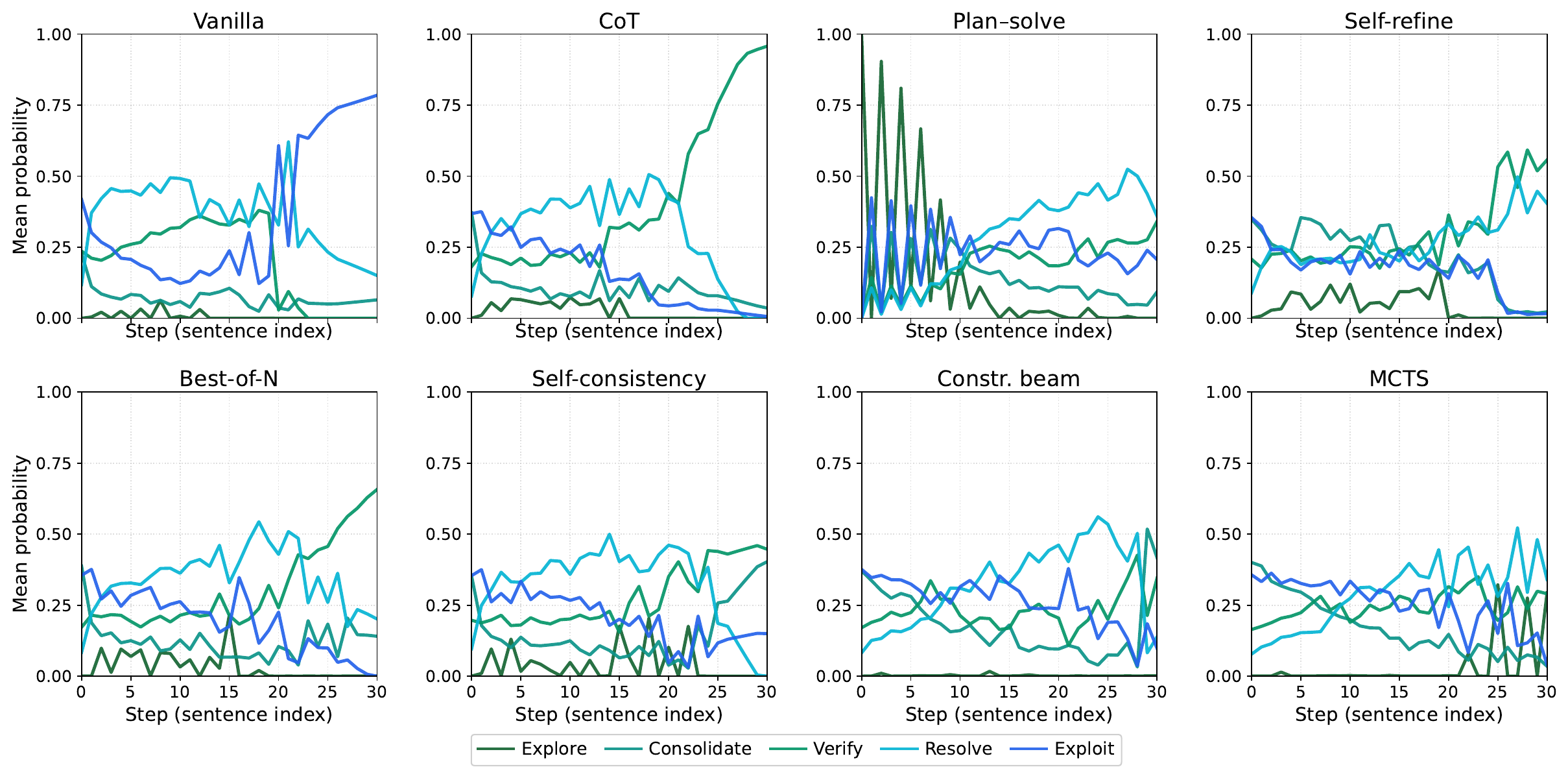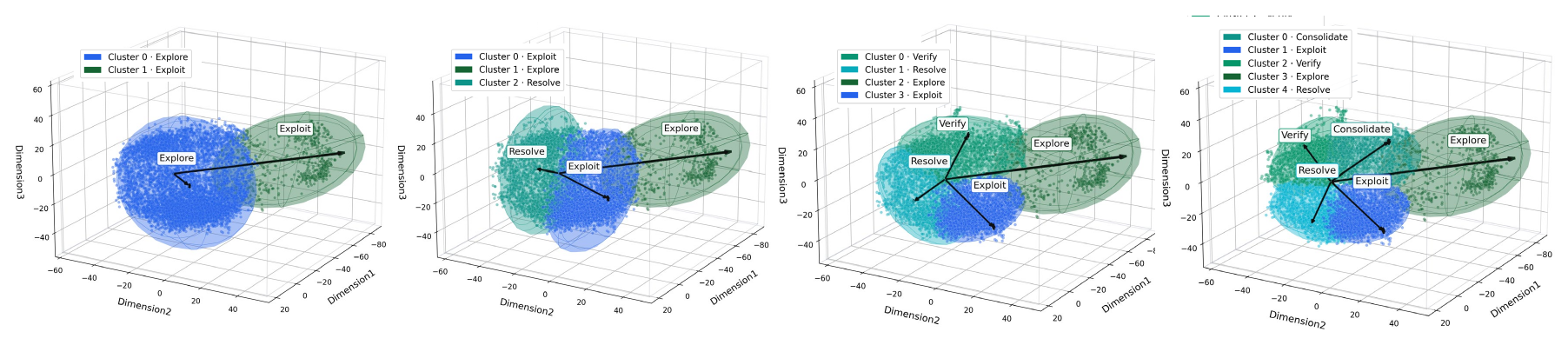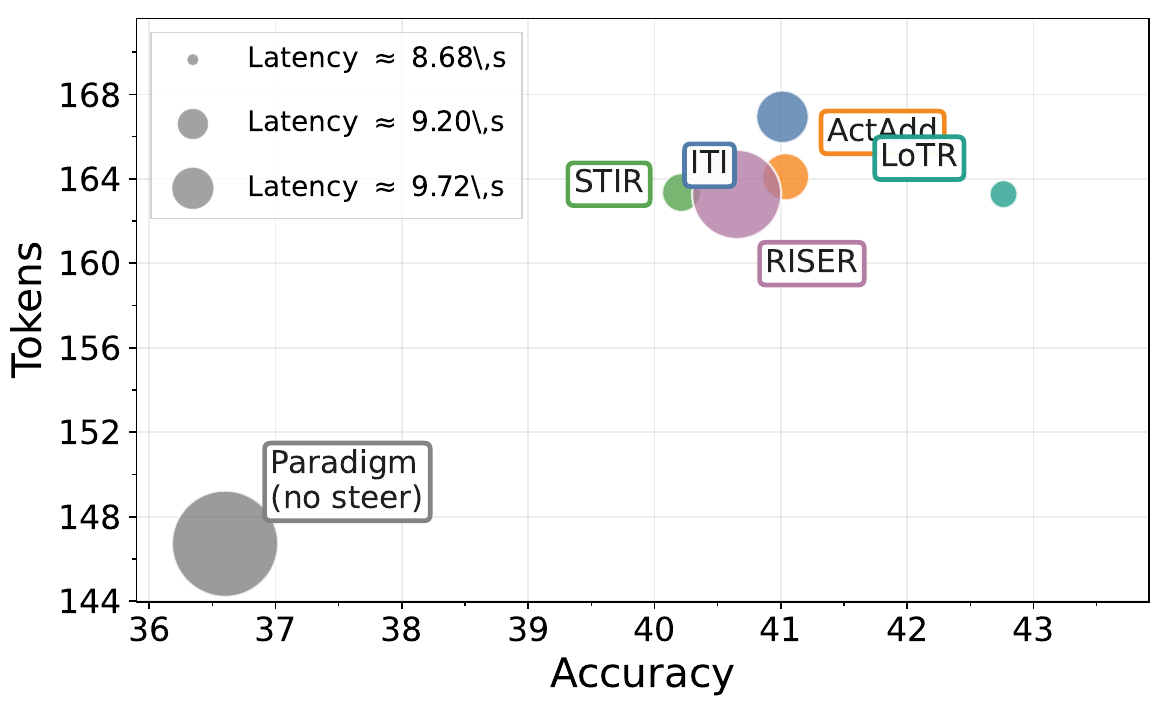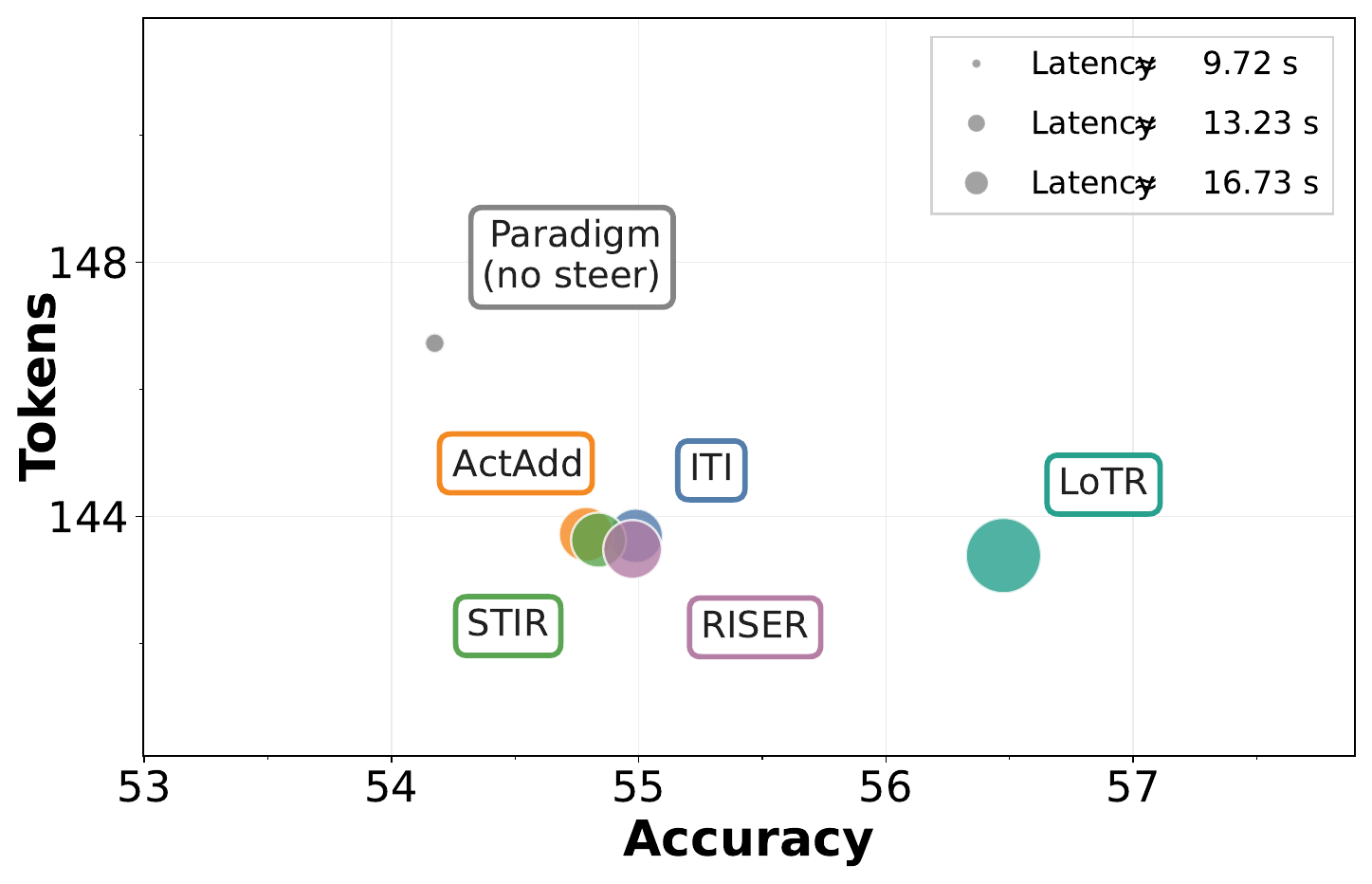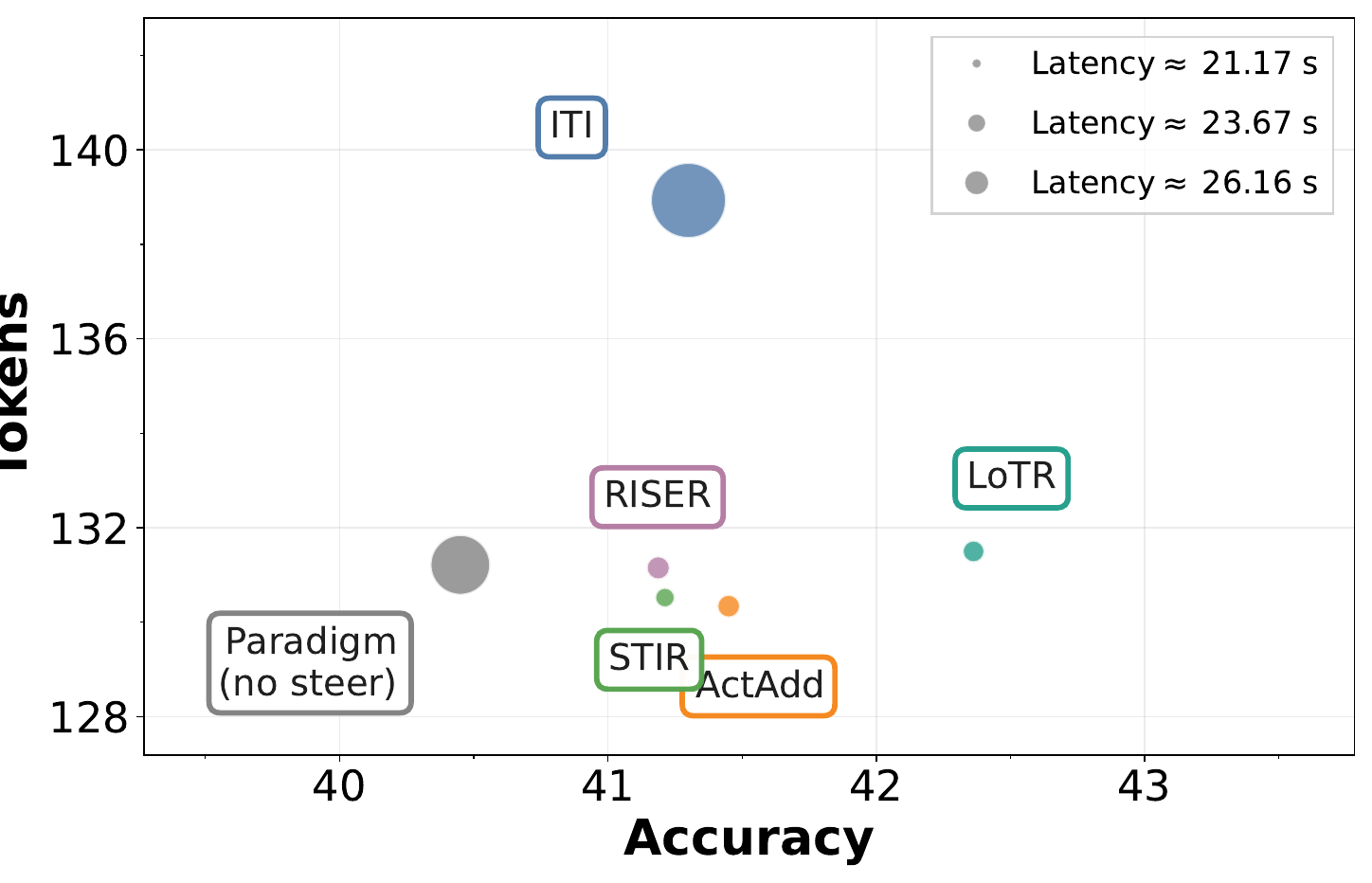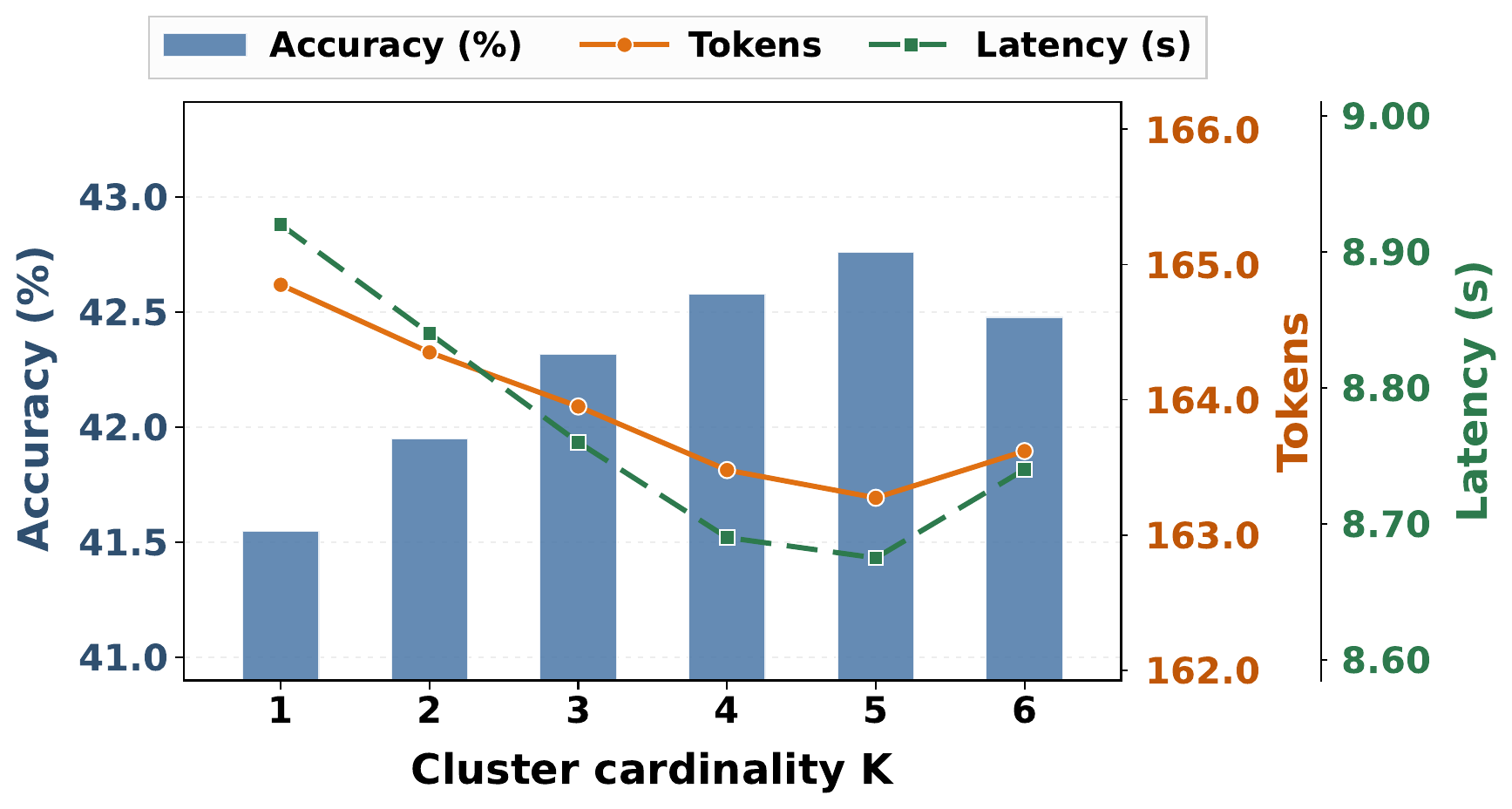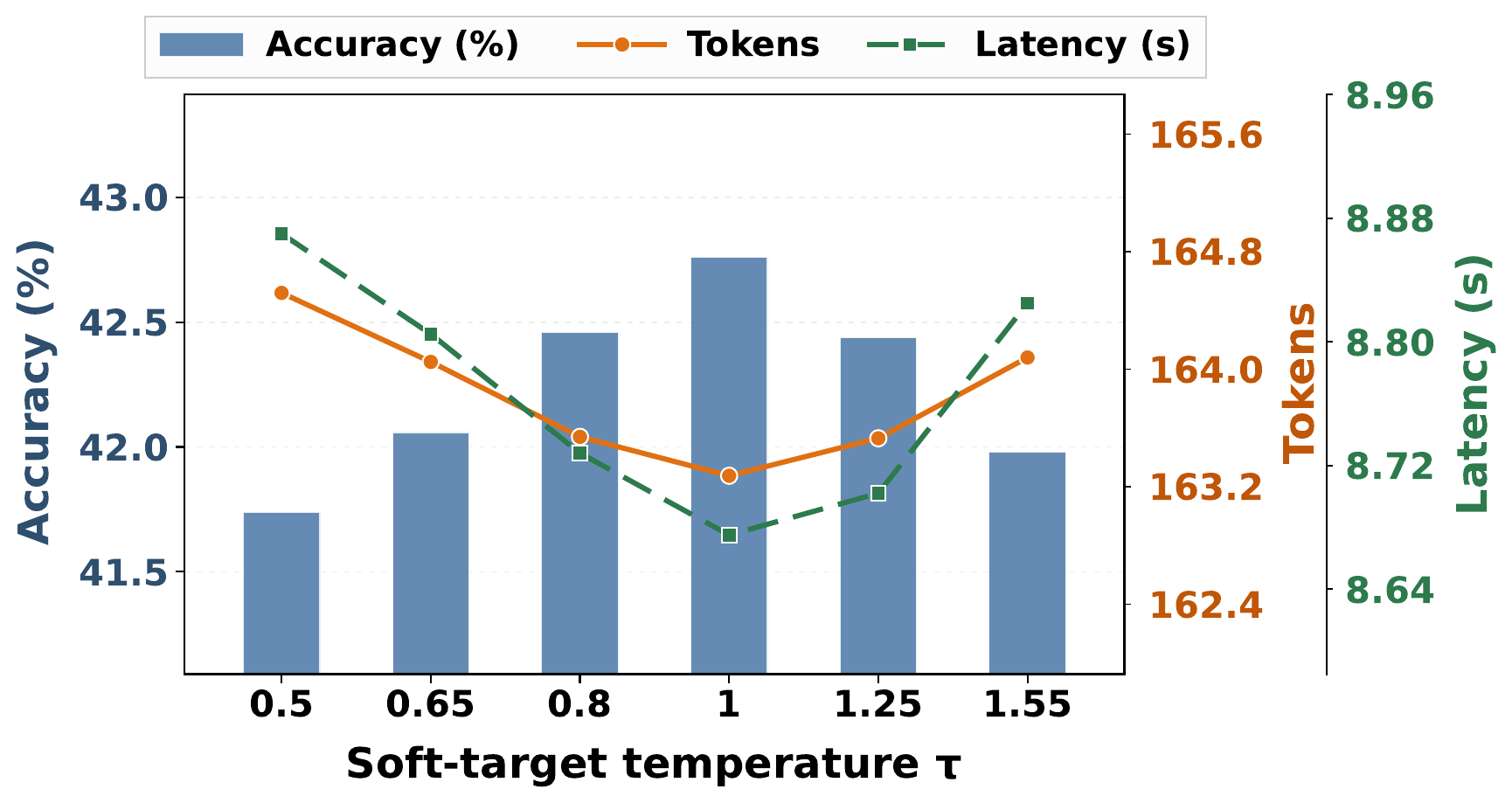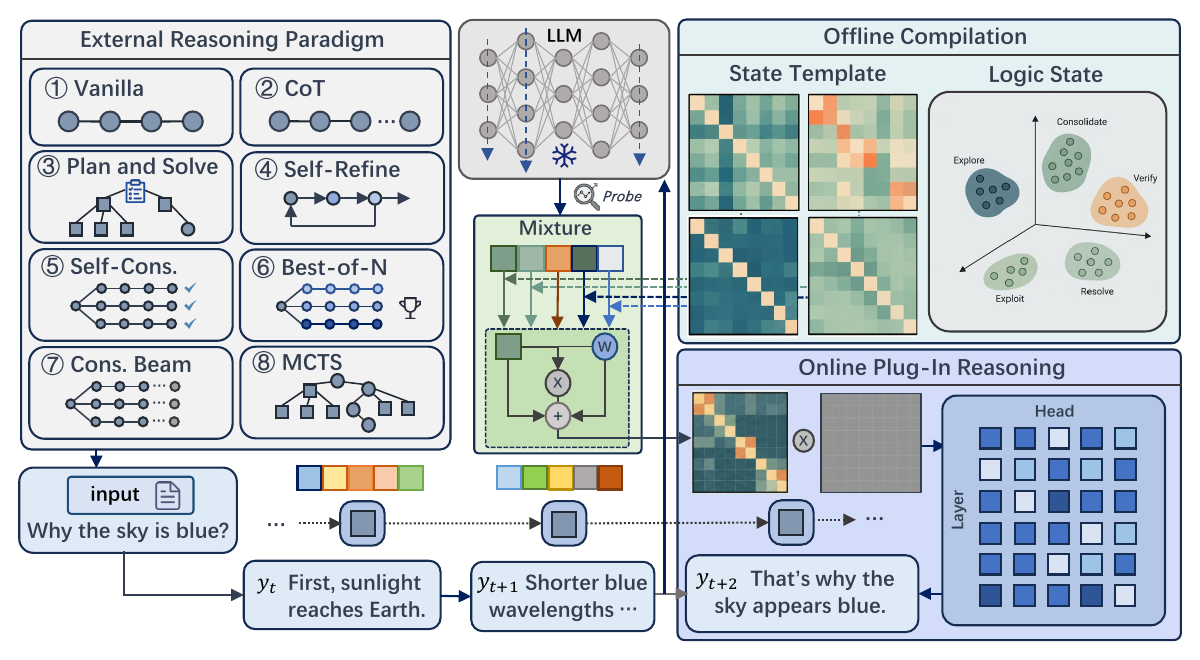
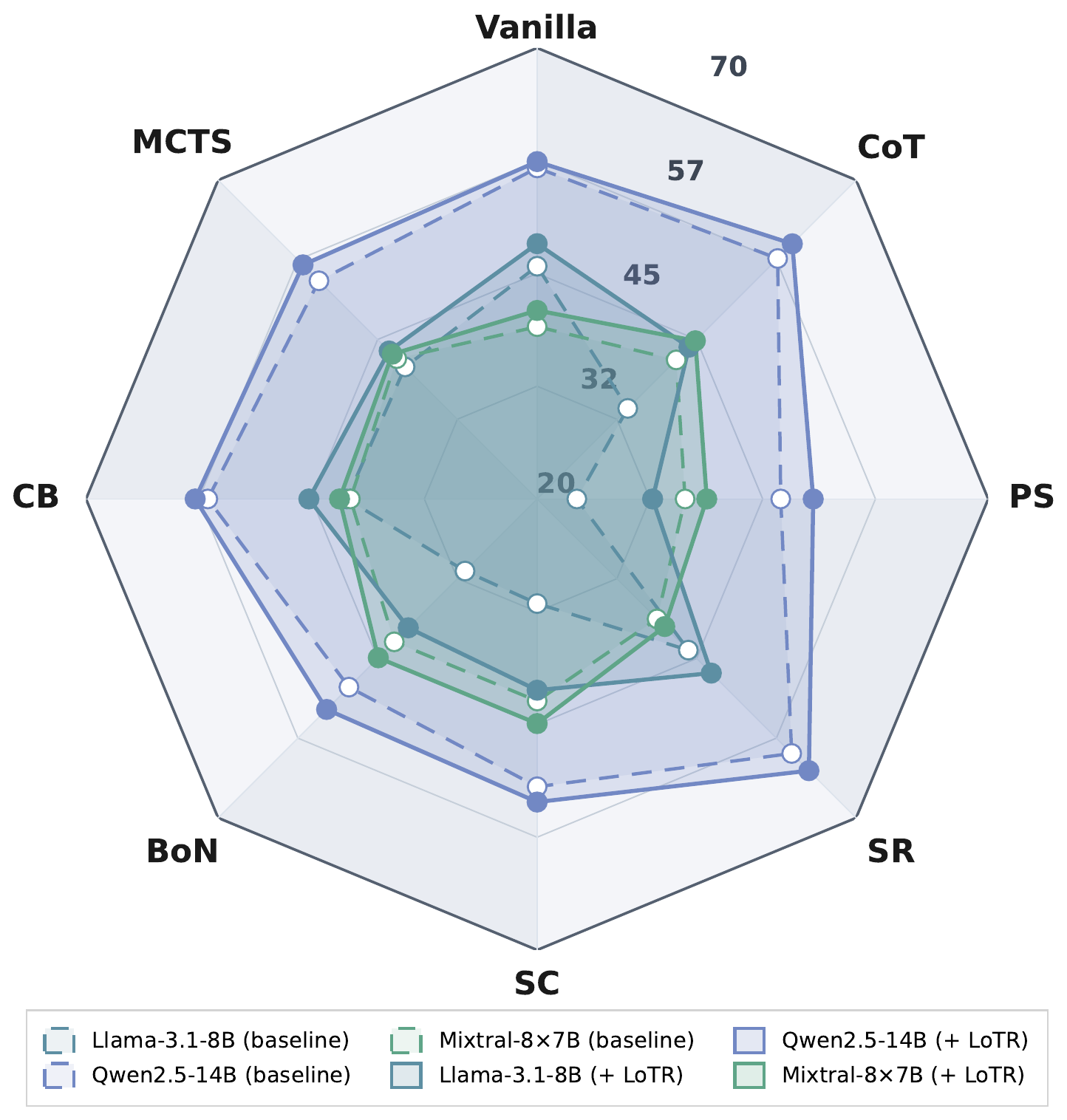
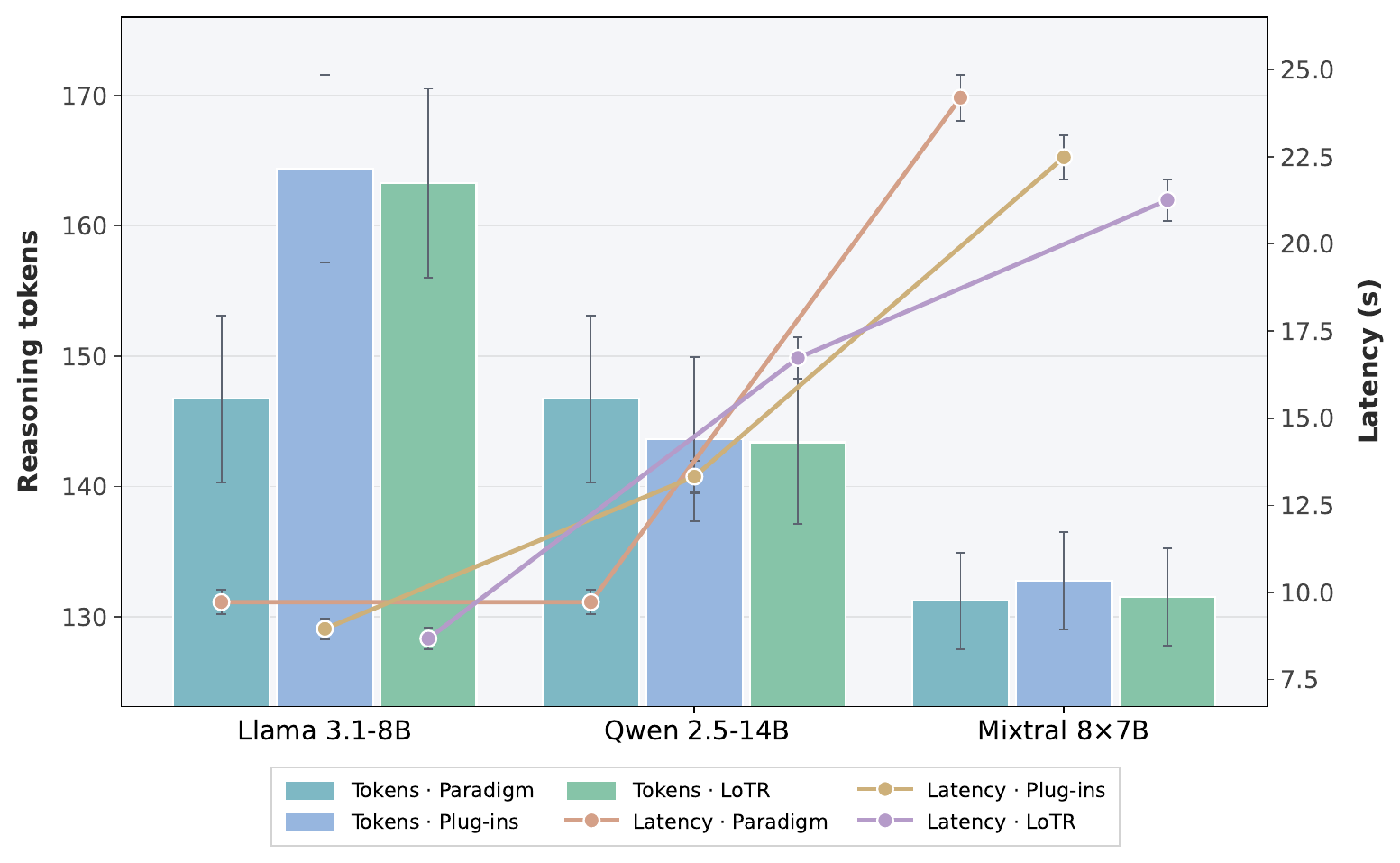
Cross-Setting Effectiveness
Across 3 backbones, 8 benchmarks, and 8 reasoning paradigms, LoTR improves average accuracy by 7.93% with only +3.18% reasoning tokens overall. The largest relative uplift appears on Llama-3.1-8B (16.67%), showing that logic-state-conditioned pathway routing can unlock substantial gains under diverse wrappers.